Tokens: The easiest way to represent tokens in your projects is with an enumeration of all 36 kinds of tokens in this list. The easiest way to print out the token names in project 1 is with an array of character strings. The following C program illustrates the idea with just the first three token types in the list:
#include <stdio.h>
enum tokens {IFTOK, THENTOK, ELSETOK};
main()
{
enum tokens a, b ; /* Declares a and b to be tokens. */
char *TokenName[] = {"IFTOK", "THENTOK", "ELSETOK"};
a = IFTOK; /* Sets the value of a to IFTOK */
b = ELSETOK; /* Sets the value of b to ELSETOK */
/* Print the names of tokens b and a */
printf("%s %s\n" , TokenName[b], TokenName[a] ) ;
return;
}
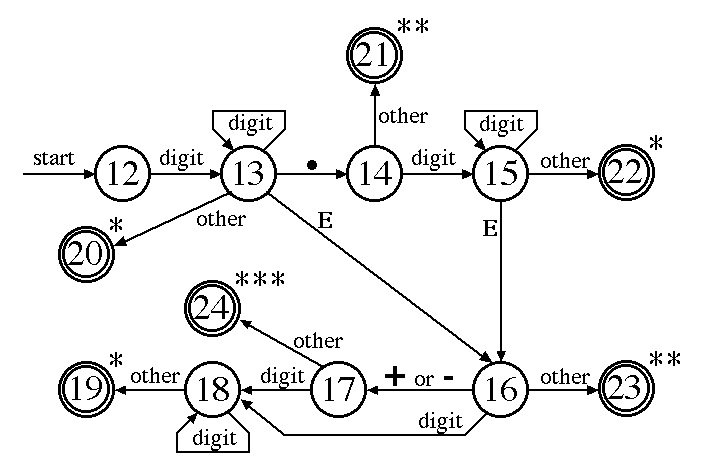
Lexical Analyzer: Projects 2 and 3 are simpler if the lexical
analyzer is written as a function with no arguments and no return value,
void GetToken(void): each time it is called it returns the
token-type in one global variable (lookahead) and a pointer in
another global variable (attributes).
In C, reading the input file with fscanf and "%s" ignores spaces, tabs, and newlines so only comments need to be removed from the source file. fscanf could return a whole line if the line has no white-space so the input buffer should hold at least 80 characters.
Between calls the lexical analyzer must remember where the next lexeme starts so the input buffer and the buffer index should be globals. INSERT must also use a global to remember the last entry number it used.
The ctype.h header file has some useful functions for determining if an input character is a letter and/or a digit: isdigit returns true if and only if the character is a decimal digit; isalpha returns true if and only if the character is a letter; and isalnum returns true if and only if the character is a decimal digit or a letter.
Before reading the source input file, pre-load the symbol table with the lexemes of all tokens except identifiers and numbers (insert the plus-sign and minus-sign as UNARYOP tokens,) then the simplest lexical analyzer uses the following logic:
If the token-type is a UNARYOP then check the type of the previous token (which should still be stored in lookahead) - if the previous token-type is ID, NUM, RPAR, or RBRK then return ADDOP instead of UNARYOP. Always return a pointer to the symbol table entry so later compiler phases can distinguish between the plus and minus signs.
Type-Expression Fields: To prepare for projects 2 and 3, the lexical analyzer can set the type-expression fields of NUM tokens and BCONST tokens. If a number is an integer (no fraction and no exponent) then set the type-expression field of its entry to "i". If a number is a real (with a fraction and/or an exponent) then set the type-expression field of its entry to "r". When the "true" and "false" lexemes are pre-loaded into the symbol table, set the type-expression field of their entries to "b" for boolean.
Main Program: The main program opens the input and output files, sets current_scope to 0, and pre-loads the symbol table with all the keywords, etc. Then it uses a loop to call GetToken() each loop iteration. Every time GetToken returns, the main program outputs a line with the token-type spelled out, followed by one or more spaces and/or tabs, followed by the lexeme of the symbol table entry, followed by one or more spaces and/or tabs, followed by the entry-number. The DOT token occurs at the end of each test file and only at the end so instead of checking for end-of-file on the input file, the main program can exit the loop after outputting a DOT-token line.
Testing Project 1: Test your project using test1in as an input file - use a Web browser to down-load the file into your directory and then an editor to remove the HTML-stuff at the beginning and end. The output for test1in should look like test1out.
{kind=link}