| expr | --> | term rest |
| rest | --> | +
term rest | - term rest |
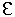 |
| term | --> | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
[4.1] - The Role of the Parser
Figure 4.1 shows the position of the parser in a compiler: basically it asks the lexical analyzer for a token whenever it needs one and builds a parse tree which is fed to the rest of the front end. In practice, the activities of the rest of the front end are usually included in the parser so it produces intermediate code instead of a parse tree.
There are universal parsing methods that will parse any grammar but they are too inefficient to use in compilers. Almost all programming languages have such simple grammars that an efficient top-down or bottom-up parser can parse a source program with a single left-to-right scan of the input.
Another role of the parser is to detect syntax errors in the source, report each error accurately and recover from it so other syntax errors can be found.
Syntax Error Handling: For some examples of common syntax errors consider the Pascal program in example 4.1 of the text:
(1) program prmax(input, output);
(2) var
(3) x, y : integer;
(4) function max(i:integer; j:integer) : integer;
(5) {return maximum of integers i and j}
(6) begin
(7) if i > j then max := i
(8) else max := j
(9) end;
(10) begin
(11) readln (x,y);
(12) writeln (max(x,y))
(13) end.
Errors in punctuation are common. For example: using a comma instead of a
semicolon in the argument list of a function declaration (line 4); leaving
out a mandatory semicolon at the end of a line (line 4); or using an
extraneous semicolon before an else (line 7).
Operator errors often occur: for example, using = instead of := (line 7 or 8).
Keywords may be misspelled: writelin instead of writeln (line 12).
A begin or end may be missing (line 9). Usually difficult to repair.
Error reporting: A common technique is to print the offending line with a pointer to the position of the error. The parser might add a diagnostic message like "semicolon missing at this position" if it knows what the likely error is.
Error-Recovery Strategies: The parser should try to recover from an error quickly so subsequent errors can be reported. If the parser doesn't recover correctly it may report spurious errors.
| parameter_list | --> | identifier_list : type | parameter_list ; identifier_list : type | parameter_list , {error; writeln("comma should be a semicolon")} identifier_list : type |
[4.2] - Context-Free Grammars
Context-free grammars are defined in section 2.2: they are a convenient way of describing the syntax of programming languages. A string of terminals (tokens) is a sentence in the source language of a compiler if and only if it can be parsed using the grammar defining the syntax of that language.
Derivations
Section 2.4 describes parsing as the construction of a parse tree whose root is the start symbol and whose leaves are the tokens in the input stream. Parsing can also be described as a re-writing process: each production in the grammar is a re-writing rule that says that an appearance of the nonterminal on the left-side can be replaced by the string of symbols on the right-side. An input string of tokens is a sentence in the source language if and only if it can be derived from the start symbol by applying some sequence of re-writing rules.
Example: Section 2.4 of these course notes shows an example of building a parse tree to prove that 9-5+2 is a sentence in the language described by the following grammar:
| expr | --> | term rest |
| rest | --> | +
term rest | - term rest |
|
| term | --> | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
The example constructed the parse tree in seven steps where each step used a production in the grammar. Below is a table to show what occurs when the production of each step is used as a re-writing rule on a symbol string: the initial symbol string just contains the start symbol, expr .
| Steps | Productions (Re-writing Rules) |
Symbol Strings (Sentential Forms) |
|---|---|---|
| expr | ||
| 1 | expr --> term rest | term rest |
| 2 | term --> 9 | 9 rest |
| 3 | rest --> - term rest | 9 - term rest |
| 4 | term --> 5 | 9 - 5 rest |
| 5 | rest --> + term rest | 9 - 5 + term rest |
| 6 | term --> 2 | 9 - 5 + 2 rest |
| 7 | rest --> | 9 - 5 + 2 |
Only the last symbol string in the derivation is a sentence in the language: earlier symbol strings are not sentences because they contain nonterminals as well as terminals so they are merely sentential forms .
A derivation is usually shown as a sequence of the sentential forms separated by double-line arrows, ==>. The first sentential form in the sequence is the start symbol of the grammar and the last sentential form is a sentence in the language. For example, the foregoing derivation for 9 - 5 + 2 is usually written:
| expr | ==> | term rest |
| ==> | 9 rest | |
| ==> | 9 - term rest | |
| ==> | 9 - 5 rest | |
| ==> | 9 - 5 + term rest | |
| ==> | 9 - 5 + 2 rest | |
| ==> | 9 - 5 + 2 |
The double-line arrow, ==>, is read as "derives in one step". The symbol, ==>*, is read as "derives in zero or more steps". Thus, expr ==>* 9-5+2 because:
Each step of a derivation replaces a single nonterminal in the sentential form with a string of symbols on the right side of some production for that nonterminal. When there are two or more nonterminals in the sentential form which nonterminal gets replaced? It doesn't matter, the parse tree can be built several different ways. Having chosen the nonterminal to be replaced which of its re-writing rules should be applied? This does matter, in an ambiguous grammar choosing the wrong re-writing rule (production) will construct a different parse tree for the same token stream. If the grammar is unambiguous then the correct re-writing rule must be selected at each step or the parse tree can't be built.
The foregoing derivation of 9-5+2 is called a leftmost derivation because each step replaces the leftmost nonterminal in the sentential form. Each step of a rightmost derivation step replaces the rightmost nonterminal in the sentential form:
| Steps | Productions (Re-writing Rules) |
Symbol Strings (Sentential Forms) |
|---|---|---|
| expr | ||
| 1 | expr --> term rest | term rest |
| 2 | rest --> - term rest | term - term rest |
| 3 | rest --> + term rest | term - term + term rest |
| 4 | rest --> | term - term + term |
| 5 | term --> 2 | term - term + 2 |
| 6 | term --> 5 | term - 5 + 2 |
| 7 | term --> 9 | 9 - 5 + 2 |
Note that both derivations of 9-5+2 used the same seven re-writing rules but in a different order. Why does the parsing process described in section 2.4 construct the parse tree using the leftmost derivation? Both derivations build the parse tree top-down but the leftmost derivation builds the left-side of the tree first and the rightmost derivation builds the right-side first. The parsing process in section 2.4 chooses the leftmost derivation because it reads the input token string from left-to-right.
A bottom-up parser performs a derivation in reverse order: starting with the sentence and ending with the start symbol of the grammar. Each step in a bottom-up parser performs a production of the grammar in reverse: reducing the sentential form by finding a string of symbols in the form that correspond to the right-side of some production and replacing that string with the nonterminal of that production.
What kind of derivation should a bottom-up parser perform in reverse order? Note that the last step of a leftmost derivation builds the rightmost corner of the parse tree while the last step of a rightmost derivation builds the leftmost corner. A bottom-up parser reads the input tokens from left-to-right so it performs a rightmost derivation in reverse order.
Parsers are classified by the order they read the input tokens and by the kind of derivations they perform. A top-down parser that reads the input tokens from left-to-right and performs a leftmost derivation is an LL -parser. A bottom-up parser that reads the input tokens from left-to-right and performs a rightmost derivation is an LR -parser.
[4.3] - Writing a Grammar
Context-free grammars can describe a larger class of languages than regular expressions. Most of the syntax of a programming language can be described with a context-free grammar but there are still certain constraints that can't be so described (such as not using a variable before it's declared.) Those constraints are checked by the semantic analyzer.
Regular Expressions vs. Context-Free Grammars: Every construct that can be described a regular expression can also be described by a grammar. For example, the regular expression: (a|b)*abb and the grammar:
| A0 | -- > | a A0 | b A0 | a A1 |
| A1 | -- > | b A2 |
| A2 | -- > | b A3 |
| A3 | -- > |
|
describe the same language: the set of strings of a's and b's ending in abb. Then why do we describe a lexical analyzer in terms of regular expressions when we could've used a grammar instead? The text lists four reasons: (1) lexical analysis doesn't need a notation as powerful of as a grammar; (2) regular expressions are easier to understand; (3) more efficient lexical analyzers can be implemented from regular expressions; and (4) separating lexical analysis from nonlexical analysis splits the front end of a compiler into two manageable-size parts.
Verifying the Language Generated by a Grammar: A grammar G generates a language L if and only if: (1) every string generated by G is in L ; and (2) every string in L can indeed be generated by G . Example 4.7 in the text shows that the grammar:
| S | --> |
|
(S )S
|
generates all strings of balanced parentheses.
Eliminating Ambiguity: Most programming languages allow both if-then and if-then-else conditional statements. For example, the productions for a statement are:
| stmt | --> | if expr then stmt | |
| | if expr then stmt else stmt | |||
| | other |
where other stands for all other statements. Any such language has a "dangling-else" ambiguity: figure 4.6 shows two different parse trees for the sentence:
where E1 and E2 are logical expressions and S1 and S2 are statements. If E1 is false should S2 be executed or not? It depends on which parse tree of figure 4.6 is used. All languages with the "dangling-else" ambiguity resolve the problem by using the first parse tree in figure 4.6: each else is matched with the closest previous unmatched then. The grammar for a statement can be modified to enforce this rule:
| stmt | --> |
matched_stmt | unmatched_stmt |
| matched_stmt | --> | if expr then matched_stmt
else matched_stmt | other |
| unmatched_stmt | --> |
if expr then stmt | if expr then matched_stmt else unmatched_stmt |
Elimination of Left Recursion
A grammar is left recursive if it contains a nonterminal A such that there is a chain of one or more derivations A ==> . . . ==> A Z where Z is a (possibly empty) string of symbols. Top-down parsing methods can't handle left recursion so a method of eliminating it is needed. Algorithm 4.1 in the text changes all left recursion into immediate left recursion and then eliminates it.
Immediate Left Recursion: Immediate left recursion occurs where the grammar has a production for a nonterminal that begins with the same nonterminal: section 4.3 in the text shows the general method for eliminating it:
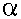 1 |
A2 | . . . |
Am |
1 |
A2 | . . . |
Am |
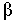 1 |
2 | . . . |
n
1 |
2 | . . . |
n
where each and is a string of
grammar symbols and no begins with A.
To eliminate the immediate left recursion a new nonterminal, A', is
added to the grammar with the productions:
1 A' |
2 A' | . . . |
m A' |
and the productions for nonterminal A are changed to:
1 A' |
2 A' | . . . |
n A'As an example consider the productions for id_list in the grammar for the coding projects:
| id_list | --> | ID |
id_list COMMA ID |
In this example, there is only one ,
COMMA ID, and only one , ID. To eliminate the immediate
left recursion, a new nonterminal, id_list_rest, is added to the grammar,
and the productions for id_list and id_list_rest are:
| id_list | --> | ID id_list_rest |
| id_list_rest | --> | COMMA ID
id_list_rest |
|
As another example consider the productions for declarations in the grammar for the coding projects:
| declarations | --> | declarations VARTOK declaration SEMICOL |
|
There is only one , VARTOK declaration SEMICOL,
and the only , is the empty string,
. A new nonterminal, declarations_rest,
is added to the grammar, and the productions for declarations
and declarations_rest are:
| declarations | --> | declarations_rest |
| declarations_rest | --> | VARTOK declaration SEMICOL declarations_rest |
|
This example illustrates what occurs when the only
is the empty string. declarations now has only one production:
declarations --> declarations_rest and this is the
only production with declarations_rest on the right-side.
We might as well change the name of declarations_rest to
declarations and change the grammar to read:
| declarations | --> | VARTOK declaration SEMICOL declarations |
|
Left Factoring
Left factoring is useful for producing a grammar suitable for a predictive parser. As an example consider the productions for statement in the grammar for the coding projects:
| statement | --> | variable
ASSIGNOP expr | procedure_call | block | IFTOK expr THENTOK statement ELSETOK statement | WHILETOK expr DOTOK statement |
Three of the productions for statement begin with the nonterminals: variable, procedure_call, and block. The productions for these three nonterminals are:
| variable | --> | ID | ID LBRK expr RBRK |
| procedure_call | --> | ID | ID LPAR expr_list RPAR |
| block | --> | BEGINTOK opt_statements ENDTOK |
In the productions for statement we replace nonterminals: variable, procedure_call, and block, by the right-sides of their productions to obtain:
| statement | --> |
ID ASSIGNOP expr | ID LBRK expr RBRK ASSIGNOP expr | ID | ID LPAR expr_list RPAR | BEGINTOK opt_statements ENDTOK | IFTOK expr THENTOK statement ELSETOK statement | WHILETOK expr DOTOK statement |
Now every production for statement begins with a terminal but four of the productions begin with the same terminal, ID, so we add a new nonterminal, statement_rest, to the grammar and left factor ID out of those four productions to obtain:
| statement | --> |
ID statement_rest | BEGINTOK opt_statements ENDTOK | IFTOK expr THENTOK statement ELSETOK statement | WHILETOK expr DOTOK statement |
| statement_rest | --> |
ASSIGNOP expr | LBRK expr RBRK ASSIGNOP expr | LPAR expr_list RPAR | |
Note that the alternative productions for statement start with different terminals so a predictive parser will have no trouble selecting the correct production. The same is true for the alternative productions for statement_rest.
In this example, nonterminals variable and procedure_call no longer appear on the right-side of any production in the project grammar so they can be deleted (along with their productions.) Nonterminal block still appears on the right-sides of productions for program and subroutine so it must be kept in the grammar.
Non-Context-Free Language Constructs
Programming languages insist that variables be declared before being used but there is no way of incorporating this constraint in a grammar. Another constraint that can't be enforced in a grammar is that the number and types of arguments in a function call agree with the number and types of the formal parameters in the definition of the function. Checks for these kinds of constraints are performed in the semantic analyzer.