| E | --> | T E' |
| E' | --> | 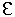 | + T E'
| + T E'
|
| T | --> | F T' |
| T' | --> |
| * F T'
|
| F | --> | id | (E ) |
As mentioned in section 2.3, syntax-directed translation incorporates the operations of the semantic analyzer and code generator into the parser so it produces the final translation instead of a parse tree.
[4.4] - Top-Down Parsing
Transition Diagrams for Predictive Parsers
One can represent the actions of a predictive parser with a transition diagram for each nonterminal of the grammar. For example, figure 4.10 shows the diagrams for the following grammar:
| E | --> | T E' |
| E' | --> |
| + T E'
|
| T | --> | F T' |
| T' | --> |
| * F T'
|
| F | --> | id | (E ) |
The parser starts at the starting state of the start symbol (state 0 in figure 4.10) and stops when it reaches the end state (or accepting state) of the start symbol (state 2 in figure 4.10).
To traverse an edge labeled with a nonterminal the parser goes to the starting state of the diagram for that nonterminal and returns to the original diagram when it has reached the end state of that nonterminal. The parser has a stack to keep track of these actions. For example, to traverse the T-edge from state 0 to state 1, the parser stacks state 1 on the top of the stack, traverses the T-diagram from state 7 to state 9 and then goes to state 1 after popping it off the stack.
An edge labeled with a terminal can be traversed when the current input token equals that terminal: when such an edge is traversed the current input token is replaced with the next input token. For example, the +-edge from state 3 to state 4 can be traversed when the parser is in state 3 and the input token is +: traversing the edge will replace the + token with the next token.
An edge labeled with can be traversed if no other
edges leaving the current parser state can be traversed: the input token
remains fixed when an -edge is traversed. For example,
if the parser is in state 3 and the current input token is not a plus sign,
+, then the parser goes to state 6 and doesn't change the input token.
Transition diagrams can be simplified as shown in figure 4.11. Figure 4.12 shows that nonterminals E' and T' can be removed from the example grammar.
Nonrecursive Predictive Parsing
Figure 4.13 shows a predictive parser that doesn't use recursive descent. The program maintains a stack of grammar symbols and uses a two-dimensional M-table created from the grammar. A special symbol, $, marks the bottom of the stack and also the end of the input. The parser is initialized with the start symbol on the stack and the input pointing to the first token. The actions of the parser depend on the grammar symbol on the top of the stack, X , and the current input token, a :
If the M[X, a ] entry is a production for X then the parser pops X off the stack and pushes the symbols on the right-side of the production onto the stack (pushing the rightmost symbol of the right-side first and pushing the leftmost symbol on the right-side last.)
If the M[X, a ] is an error entry then the parser announces the error and calls an error recovery routine.
As an example, figure 4.15 shows the M-table for the following grammar:
| E | --> | T E' |
| E' | --> | |
+ T E'
|
| T | --> | F T' |
| T' | --> | |
* F T'
|
| F | --> | id | (E ) |
Generation of the M-table from the grammar will be described later. Figure 4.16 shows the moves made by the parser when the input is id + id * id. In that figure the stack is shown with the bottom on the left and the top on the right: the figure seems to make more sense when the stack is reversed as it is below:
| Stack | Input | Production |
|---|---|---|
| E$ | id+id*id$ | |
| TE'$ | id+id*id$ | E --> TE' |
| FT'E'$ | id+id*id$ | T --> FT' |
| idT'E'$ | id+id*id$ | F --> id |
| T'E'$ | +id*id$ | |
| E'$ | +id*id$ | T' --> |
| +TE'$ | +id*id$ | E' --> +TE' |
| TE'$ | id*id$ | |
| FT'E'$ | id*id$ | T --> FT' |
| idT'E'$ | id*id$ | F --> id |
| T'E'$ | *id$ | |
| *FT'E'$ | *id$ | T' --> *FT' |
| FT'E'$ | id$ | |
| idT'E'$ | id$ | F --> id |
| T'E'$ | $ | |
| E'$ | $ | T' --> |
| $ | $ | E' --> |
FIRST and FOLLOW
FIRST and FOLLOW are two functions associated with a grammar that help us fill in the entries of an M-table. The functions have other uses as well.
If Z is any string of grammar symbols then FIRST(Z ) is the set
of all terminals that begin strings derived from Z. If Z ==>*
then is also in FIRST(Z ).
If A is a nonterminal then FOLLOW(A ) is the set of all terminals that can appear immediately after A in some sentential form derived from the start symbol. If A appears as the rightmost symbol in some sentential form then the end of input, $, is also in FOLLOW(A ).
The text lists some rules to apply to find FIRST and FOLLOW. For the example grammar at the beginning of this section we have:
| A | FIRST(A) | FOLLOW(A) |
|---|---|---|
| E | ( id | ) $ |
| E' | + |
) $ |
| T | ( id | + ) $ |
| T' | * |
+ ) $ |
| F | ( id | + * ) $ |
Construction of Predictive Parsing Tables
Algorithm 4.4 in the text shows how to use the FIRST and FOLLOW functions to fill in the entries of the M-table for a nonrecursive predictive parser. Figure 4.15 shows the M-table for the example grammar of this section.
LL(1) Grammars
Should algorithm 4.4 put two or more different productions in the same entry of the M-table it means that the grammar is ambiguous and/or left-recursive and/or not left-factored. A grammar is an LL(1)- grammar if and only if its M-table has no entries that are multiply-defined.
Figure 4.17 is the M-table for the following grammar:
| stmt | --> | a | if expr then stmt opt_else |
| opt_else | --> |
| else stmt |
| expr | --> | b |
There are two productions in the M(opt_else, else) entry so the
grammar is ambiguous. To resolve the ambiguity we must delete either the
opt_else --> else stmt production or the
opt_else --> production from this entry.
Since the opt_else --> else stmt production is the
only production in the grammar that handles the else token we must keep
it and drop the opt_else --> production.
This choice corresponds with associating else tokens with the closest
previous unmatched then tokens.
Error Recovery in Predictive Parsing
The stack of a nonrecursive predictive parser shows what the parser hopes to match with the remainder of the input. The parser detects an error whenever there is a terminal on the top of the stack that doesn't agree with the current input token or when it consults an M-table entry marking an error. The FIRST and FOLLOW sets of a grammar can be used to generate meaningful error messages and expedite error recovery. The text describes five heuristics one can use.
[5.1] - Syntax-Directed Definitions
A syntax-directed definition generalizes a context-free grammar by associating a set of attributes which each node in a parse tree. Each attribute gives some information about the node. For example, attributes associated with an expression-node may gives its value, its type, or its location in memory, etc. There are two kinds of attributes:
Since the root of a parse tree has no parent and no siblings, the start symbol of a grammar can have no inherited attributes. Information about terminal symbols at the leaves of a parse tree comes from the lexical analyzer (or in a field of a symbol table entry that the lexical analyzer points to) and we treat this information as synthesized.
A parse tree showing the values of attributes at each node is called an annotated parse tree: computing the attribute values is called annotating or decorating the tree.
Form of a Syntax-Directed Definition: Semantic rules are associated with the productions of the grammar to show the relationships between the attributes of each parent node and its children nodes. For example, assume there is a production in a grammar, X --> Y Z , that constructs a parse tree with nodes Y and Z as children of node X and further assume there is an attribute, a, attached to each of the nodes as shown below:
___
| |
| X |X.a
|___|
/ \
___/ \___
| | | |
| Y |Y.a | Z |Z.a
|___| |___|
If there is a semantic rule, X.a := f(Y.a, Z.a), associated with production
X --> Y Z then attribute X.a of the parent node is
a synthesized attribute which can be evaluated by applying function f to
attributes Y.a and Z.a of its children. On the other hand, if there is a
semantic rule, Z.a := f(X.a, Y.a), associated with production X -->
Y Z then attribute Z.a of the right child is an inherited
attribute which can be evaluated by applying function f to attributes X.a and
Y.a of its parent and sibling.
As an example, figure 5.2 is a syntax-directed definition of a simple desk calculator. In this example, the val attribute of every node is a synthesized attribute. Note the use of subscripts in a production like E --> E +T where the same grammar symbol appears more than once: the E child node is given a subscript of 1 to distinguish it from the E parent node (in the production and in the associated semantic rule.)
S-attributed definitions: A syntax-directed definition is an S-attributed definition if all attributes are synthesized. Figure 5.2 is an example of an S-attributed definition. A parse tree for an S-attributed definition can always be annotated by evaluating the semantic rules for the attributes at each node bottom-up, from the leaves to the root.
Inherited Attributes: Inherited attributes are useful for passing type information in declarations. Figure 5.4 shows a syntax-directed definition for a declaration in C. It uses a synthesized attribute, T.type , to collect the type of the declaration and an inherited attribute, L.in , to pass the type down through the list of id nodes in the declaration so their symbol table entries can be updated.
[5.2] - Construction Of Syntax Trees
A syntax tree or an abstract syntax tree (AST) is a condensed form of a parse tree with the operators and keywords associated with interior nodes rather than with the leaves. For example, the production: stmt --> if expr then stmt appears in a syntax tree like:
_________
| |
| if-then |
|_________|
______/ \______
| | | |
| expr | | stmt |
|______| |______|
rather than in a parse tree like:
______________
| |
| stmt |
|______________|
/ ______/ | \______
| | | | | |
| | expr | | | stmt |
| |______| | |______|
| |
if then
As another example consider the parse tree constructed for 9 - 5 + 2 in
section 2.4 of these course notes. The syntax tree for this expression is
simply:
_____
| |
| add |
|_____|
/ \
__________/ |
| | |
| subtract | |
|__________| |
/ \ |
/ \ |
| | |
9 5 2
Figure 5.9 shows a syntax-directed definition for constructing a syntax tree for an expression. Attribute nptr is a pointer to a node of the syntax tree. When function mknode is given an operator and pointers to two nodes it creates a parent node for those two nodes labeled with the operator and returns a pointer to the node it creates. Similarly, function mkleaf creates a leaf and returns a pointer to it.
[5.4] - L-Attributed Definitions
In general, an inherited attribute of a node depends on attributes of its parent node and on attributes of its sibling nodes. It is often the case where an inherited attribute of a node depends only on the inherited attributes of its parent node and on attributes of sibling nodes to its left: i.e., there is no dependence on a synthesized attribute of the parent nor on any attribute of a sibling node on the right. If this is true of all inherited attributes in a syntax-directed definition then it is L-attributed. Note that there is no restriction on the synthesized attributes of the definition; e.g., every S-attributed definition is also L-attributed.
Figure 5.18 shows the pseudo-code for recursive procedure dfvisit:
| procedure dfvisit(n : node); | ||
| begin | ||
| for | each child m of n in left-to-right order do begin | |
| evaluate inherited attributes of m ; | ||
| dfvisit(m ); | ||
| end; {for loop} | ||
| evaluate synthesized attributes of n ; | ||
| end | ||
Calling dfvisit at the root of a parse tree for an L-attributed definition will annotate the whole parse tree.
Translation Schemes: Translation schemes are introduced in section 2.3: a translation scheme is a context-free grammar (with attributes associated with the grammar symbols) where semantic actions (enclosed in braces) are inserted within the right-sides of productions. Section 2.5 of these notes shows a translation scheme for printing an infix expression in postfix notation.
A translation scheme is a convenient way of describing an L-attributed definition. As an example, assume the grammar has a production: A --> X Y and further assume that A, X, and Y, have inherited attributes A.i, X.i, and Y.i, and synthesized attributes A.s, X.s, and Y.s, respectively. Because we have an L-attributed definition:
A translation scheme would embed the following semantic actions in the production A --> X Y as follows:
| A --> | { X.i | := f(A.i ); } X |
| { Y.i | := g(A.i, X.i, X.s ); } Y | |
| { A.s | := h(A.i, X.i, X.s, Y.i, Y.s ); } |
Note the careful placement of the semantic actions in the production: if any semantic action is moved later in the production then an inherited attribute of a child won't be evaluated in time and if any action is moved earlier in the production it will try to use an argument that hasn't been evaluated.
There is no special problem with -productions in the
grammar. For example, assume
A --> is a production in the grammar and
assume that A has an inherited attribute, A.i, and a synthesized
attribute A.s, that is a function, f, of A.i. Then the
translation scheme contains:
{ A.s := f(A.i ); }
[5.5] - Top-Down Translation
This section describes how L-attributed definitions can be implemented with predictive parsers. Translation schemes are used instead of syntax-directed definitions so the order in which semantic actions and attribute evaluations should occur is shown explicitly.
Eliminating Left Recursion from a Translation Scheme
Most arithmetic operators are left-associative so it is natural to use left-recursive grammars for expressions: also there are other language constructs best described with left-recursive grammars. But left recursion must be eliminated before a predictive parser can parse a grammar. Sections 2.4 and 4.3 describe algorithms for eliminating left recursion from a grammar but what do we do when the grammar of a translation scheme is left-recursive? Can every semantic action and attribute evaluation of a translation scheme be put in its proper place when we eliminate left recursion from its grammar?
An Example: A left-recursive grammar for a list of digits separated by plus and minus signs is shown below. The parse tree for 9 - 5 + 2 is also shown:
___
| |
| E |
|___|
/ | \
___/ | \___
| | + | |
| E | | T |
|___| |___|
/ | \ |
___/ | \___ |
| | - | | 2
| E | | T |
|___| |___|
\ |
\___ |
| | 5
| T |
|___|
|
|
9 | |||
| E | --> | E + T | |
| E | --> | E - T | |
| E | --> | T | |
| T | --> | 0 | |
| T | --> | 1 | |
| T | --> | 2 | |
| T | --> | 3 | |
| T | --> | 4 | |
| T | --> | 5 | |
| T | --> | 6 | |
| T | --> | 7 | |
| T | --> | 8 | |
| T | --> | 9 |
| E | --> | E1 + T | { E.val := E1.val + T.val } |
| E | --> | E1 - T | { E.val := E1.val - T.val } |
| E | --> | T | { E.val := T.val } |
| T | --> | 0 | { T.val := 0 } |
| . . . | |||
| T | --> | 9 | { T.val := 9 } |
Eliminating left recursion from the grammar shown above produces the grammar shown below. The parse tree for 9 - 5 + 2 with this new grammar is also shown below:
___
| |
| E |
|___|
/ \
___/ \_____
| | | |
| T | | R |
|___| |_____|
| - __/ / \
| ___/ \_____
9 | | | |
| T | | R |
|___| |_____|
| + __/ / \
| ___/ \___
5 | | | |
| T | | R |
|___| |___|
| |
| |
2 | |||
| E | --> | T R | |
| R | --> | + T R | |
| R | --> | - T R | |
| R | --> |
| |
| T | --> | 0 | |
| T | --> | 1 | |
| T | --> | 2 | |
| T | --> | 3 | |
| T | --> | 4 | |
| T | --> | 5 | |
| T | --> | 6 | |
| T | --> | 7 | |
| T | --> | 8 | |
| T | --> | 9 |
node at the bottom.
A translation scheme with this new grammar needs an inherited attribute
(in ) to properly evaluate a list of digits separated by plus and
minus signs and the scheme sends the final result into the R -->
node at the bottom of the chain. The final result
should really be sent to the root of the parse tree so the translation scheme
also needs a synthesized attribute
(syn ) to move the final result from the R -->
node back up the chain of R -nodes:
| E | --> | T { R.in := T.val } R { E.val := R.syn } |
| R | --> | + T { R1.in := R.in + T.val } R1 { R.syn := R1.syn } |
| R | --> | - T { R1.in := R.in - T.val } R1 { R.syn := R1.syn } |
| R | --> |
{ R.syn := R.in }
|
| T | --> | 0 { T.val := 0 } |
| . . . | ||
| T | --> | 9 { T.val := 9 } |
Another Example: The text shows another example where the left-recursive translation scheme for constructing a syntax tree in figure 5.9 is transformed to the scheme shown in figure 5.28.
General Case: In general, there may be both right-associative operators and left-associative operators in a translation scheme. Right-associative operators pose no problem because they don't introduce left recursion. Left-associative operators make the scheme left-recursive but the left recursion can be easily eliminated from the grammar using the algorithms in section 4.3. Eliminating the left recursion changes parse trees by replacing each chain of nodes going down toward the left with a chain of nodes going down to the right. Each synthesized attribute that was originally evaluated going up the original chain is replaced by an inherited attribute that is evaluated going down the new chain. The result of the evaluation can be sent back up the new chain with another synthesized attribute.
Design of a Predictive Translator
A parse tree of any L-attributed definition can be completely annotated by calling the recursive dfvisit procedure (shown in section 5.4) for the root of the tree. In section 2.4 the construction of a recursive-descent predictive parser is described. Note that the flow of control through dfvisit is similar to the flow of control through a recursive-descent predictive parser: control flows into a node from its parent, flows in and out of each of its children (from left-to-right) and then returns to the parent. In dfvisit the inherited attributes of each node are evaluated before the node is visited and the synthesized attributes are evaluated just before control returns to the parent of the node. Changing a recursive-descent predictive parser into a predictive translator is simple: